JOIN에 이어서 서브쿼리에 대해 알아보도록 하겠다.
우선 서브쿼리란?
서브쿼리 (SBUQUERY)
하나의 SQL문 안에 포함된 또 다른 SELECT문
메인 SQL문을 위해 보조하는 역할을 하는 쿼리
정의는 이러하다. 그럼 바로 간단한 예시를 보며 어떻게 사용되는지 알아보도록하자
SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철';우선 노옹철과 이름이 같은 사람들을 가져오는 쿼리이다.
SELECT EMP_NAME
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';부서 코드가 D9인 사람들의 이름을 가져오는 코드이다.
이 둘을 합칠 때 서브쿼리를 사용하면 하나로 합쳐지며 편리해진다.
방법은 간단하다. '노옹철' 부분과 'D9'부분을 같이 포함하도록 다시 SELECT부터 작성해주면 된다.
SELECT EMP_NAME
FROM EMPLOYEE
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '노옹철');
이렇게 되면 노옹철이라는 사람이 속한 부서 코드를 가져와서 현재 부서코드에 넣으니 D9인 사람들의 이름이 출력된다.
서브쿼리의 종류
서브쿼리를 수행한 결과값이 몇행 몇열로 나오냐에 따라서 분류
단일행 서브쿼리 : 서브쿼리의 조회 결과값의 개수가 오로지 1개 일 때
다중행 서브쿼리 : 서브쿼리의 조회 결과값이 여러행일 때(여러행 한열)
다중열 서브쿼리 : 서브쿼리의 조회 결과값이 한 행이지만 컬럼이 여러개일 때
다중행 다중열 서브쿼리 : 서브쿼리의 조회 결과값이 여러행 여러컬럼일 때
>>서브쿼리의 종류가 뭐냐에 따라서 서브쿼리의 앞에 붙는 연산자 달라짐
단일행 서브쿼리
1. 단일행 서브쿼리 서브쿼리의 조회 결과값의 개수가 오로지 1개일 때(한행 한열)
일반 비교연산자사용 가능 =, !=, <, >, <= ...
- 전 직원의 평균 급여보다 급여를 더 적게받는 사원들의 사원명, 직급코드, 급여 조회
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY < (SELECT AVG(SALARY)
FROM EMPLOYEE);SELECT EMP_ID, EMP_NAME, SALARY, HIRE_DATE
FROM EMPLOYEE
WHERE SALARY = (SELECT MIN(SALARY)
FROM EMPLOYEE);이런식으로 서브쿼리 구문에 AVG, MAX, MIN와 비교연산자 사용이 가능하다.
- 부서별 급여합이 가장 큰 부서의 부서코드 급여 합
SELECT DEPT_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING (SUM(SALARY) = (SELECT MAX(SUM(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE));
부서별로 보기로 했으니 GROUP BY로 묶어주고 SALARY를 SUM으로 더해
서브쿼리로 MAX(SUM(SALARY))를 가져온다.
-추가적인 조건이 붙었을 때
- '전지연'사원과 같은 부서의 사람들의 사번, 사원명, 전화번호, 입사일, 부서명을 조회
--단, 출력시 전지연 사원은 제외
SELECT EMP_ID, EMP_NAME, PHONE, HIRE_DATE, DEPT_TITLE
FROM EMPLOYEE
JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID)
WHERE DEPT_CODE = (SELECT DEPT_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '전지연')
AND EMP_NAME != '전지연';AND를 사용해서 이어 붙여주면 된다.
다중행 서브쿼리
서브쿼리를 수행한 결과값이 여러행일 때(컬럼은 한개)
IN(서브쿼리) : 여러개의 결과값 중에서 한개라도 일치하는 값이 있다면 조회
> ANY(서브쿼리) : 여러개의 결과값 중에서 한개라도 클 경우에 조회
< ANY(서버쿼리) : 여러개의 결과값 중에서 한개라도 작을 경우에 조회
비교대상> ANY (서브쿼리의 결과값 => 값1, 값2, 값3...)
OR 표현으로 : 비교대상> 값1 OR 비교대상 > 값2 OR 비교대상 > 갑3
> ALL (서브쿼리) : 여러개의 모든 결과값들 보다 클 경우 조회
< ALL (서브쿼리) : 여러개의 모든 결과값들 보다 작을 경우 조회
비교대상> ALL (서브쿼리의 결과값 => 값1, 값2, 값3...)
AND 표현으로 : 비교대상> 값1 AND 비교대상 > 값2 AND 비교대상 > 값3...
- 유재식 또는 윤은해 사원과 같은 직급인 사원들의 사번, 사원명, 직급코드, 급여 조회
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE JOB_CODE IN (SELECT JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME IN ('윤은해', '유재식'));이렇게 IN 절을 사용해서 가져오면 된다.
- 대리 직급임에도 과장 직급 급여들 중 최소 급여보다 많이 받는 사람들의
-- 사번, 이름, 직급, 급여 조회
SELECT EMP_ID, EMP_NAME, JOB_NAME, SALARY
FROM EMPLOYEE
JOIN JOB USING (JOB_CODE)
WHERE JOB_NAME = '대리' AND
SALARY > ((SELECT MIN(SALARY)
FROM EMPLOYEE
JOIN JOB USING (JOB_CODE)
WHERE JOB_NAME = '과장'))
ORDER BY EMP_ID;이렇게 조건을 여러개 나열해서 결과를 가져올 수 있다.
ORDER BY는 항상 마지막 순번임을 잊지말자
다중열 서브쿼리
결과값은 한 행이지만 나열된 컬럼수가 여러개일 경우
- 하이유 사원과 같은 부서코드, 같은 직급 코드에 해당하는 사원들 조회
--사원명, 부서코드, 직급코드, 입사일
사용방법은 간단하다. WHERE 절에 그냥 원하는 컬럼(복수개)를 기술해주면 된다..
SELECT EMP_NAME, DEPT_CODE, JOB_CODE, HIRE_DATE
FROM EMPLOYEE
WHERE (DEPT_CODE, JOB_CODE) = (SELECT DEPT_CODE, JOB_CODE
FROM EMPLOYEE
WHERE EMP_NAME = '하이유');**주의해야할 점은 WHERE절에 쿼리와 , 서브쿼리 절에 쿼리 순서가 동일해야한다.
하나만보면 정 없으니 하나 더
- 박나라 사원과 같은 직급코드, 같은 사수를 가지고 있는 사원들의 사번, 사원명, 직급코드, 사수번호
SELECT EMP_ID, EMP_NAME, JOB_CODE, MANAGER_ID
FROM EMPLOYEE
WHERE (JOB_CODE, MANAGER_ID) = (SELECT JOB_CODE, MANAGER_ID
FROM EMPLOYEE
WHERE EMP_NAME = '박나라');다중행 다중열 서브쿼리
서브쿼리의 조회 결과값이 여러행 여러열일경우
- 각 직급별 최소급여를 받는 사원조회(사번, 사원명, 직급코드, 급여)
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY
FROM EMPLOYEE
WHERE (JOB_CODE, SALARY) IN (SELECT JOB_CODE, MIN(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE);여기서 부터 조금 햇갈릴 수 있지만 GROUP BY를 뭐로 묶을거냐 <- 이것을 잘 생각해놓는다면 괜찮다.
여러개 중에 하나이니 IN을 써야함을 잊지말자
인라인 뷰
FROM 절에 서브쿼리를 작성한 것, 서브쿼리를 수행한 결과를 마치 테이블처럼 사용
먼저 좀 자주쓰이는 기능을 보고 가자.
ROWNUM : 오라클에서 제공해주는 컬럼, 조회된 순서대로 1부터 순번을 부여해주는 컬럼
사용법은 대략 이렇다
SELECT ROWNUM, EMP_NAME, SALARY
FROM EMPLOYEE
WHERE ROWNUM <= 5
ORDER BY SALARY DESC;
이런식으로 내림차순 정렬된 값들을 우리가 설정한 ROWNUM<=5 의 값만큼가져온다.
그럼 위 코드를 인라인 뷰로 바꿔보자
SELECT ROWNUM, EMP_NAME,SALARY
FROM (SELECT EMP_NAME, SALARY
FROM EMPLOYEE
ORDER BY SALARY DESC)
WHERE ROWNUM <=5;이렇게 FROM절 안에 넣어버리면 된다.
언뜻보면 이걸 왜 이렇게 하지? 라는 생각이들면 정상이다.
필자도 배우는 도중 그런 생각이 들었지만 우리가 지금 다루는 것은 이해를 돕기위한 아주아주 간단한 코드임을 잊지말자
나중에 복잡해지면 아주 유용하게 사용하는 인라인 뷰라고 한다.
- 각 부서별 평균급여가 높은 3개의 부서 조회
SELECT DEPT_CODE, 평균급여
FROM (SELECT DEPT_CODE, ROUND(AVG(SALARY)) AS "평균급여"
FROM EMPLOYEE
GROUP BY DEPT_CODE
ORDER BY 평균급여 DESC)
WHERE ROWNUM<=3;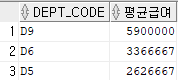
잊지말자 ROUND는 소수점을 버리는 함수였고
원하는 것으로 출력하고 싶다면 GROUP BY로 묶어주고
ROWNUM은 우리가 원하는 만큼 짤라서 값을 가져오는 함수이다.
또한 제일 윗줄의 평균급여와
FROM 절에 평균급여는 구분을 해주기위하여 저렇게 별칭을 지정해서 사용해야 에러가 나지 않고
ORDER BY는 가장 마지막에 실행되기 때문에 별칭으로 지정한 것을 인식하고 별칭으로 부를 수 있다.
- 부서별 평균급여가 270만원을 초과하는 부서들에 대해서
--부서코드, 부서별 총 급여합, 부서별, 평균급여, 부서별 사원수 조회
SELECT 부서코드, 총급여, 평균급여, 사원수
FROM (SELECT DEPT_CODE AS "부서코드", SUM(SALARY) AS "총급여", AVG(SALARY) AS "평균급여", COUNT(*) AS"사원수"
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING AVG(SALARY) > 2700000);이것또한 마찬가지이다.
WINDOW FUNCTION
순위를 매기는 함수
RANK() OVER(정렬기준) | DANSE_RANK() OVER(정렬기준)
RANK() OVER(정렬기준) : 동일한 순위 이후의 등수를 동일한 인원 수 만큼 건너뛰고 순위계산
DANSE_RANK() OVER(정렬기준) : 동일한 순위가 있다고 해도 그 다음 등수를 무조건 1씩 증가시킴
무조건 SELECT절에서만 사용 가능
- 급여가 높은 순서대로 순위를 매겨서 조회
SELECT EMP_NAME, SALARY, RANK() OVER(ORDER BY SALARY DESC)
FROM EMPLOYEE;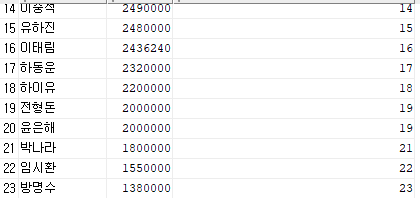
순차적으로 조금씩 오르다가 공동 19등이 나온 이후로 20등을 건너뛰고 21등이 나온 것을 볼 수 있다.
위에 정리했듯 RANK() OVER 의 특징은 동일한 순위 이후의 등수를 동일한 인원 수 만큼 건너뛰고 순위계산이다.
그럼 DESNE_RANK() OVER을 보자
SELECT EMP_NAME, SALARY, DENSE_RANK() OVER(ORDER BY SALARY DESC)
FROM EMPLOYEE;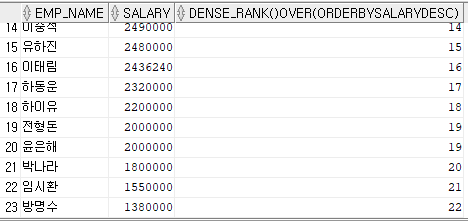
이건 공동 19등 이후에 바로 20등이 나온 것을 볼 수 있다.
우리에게 익숙한 것은 아마도 DENSE 방식이 아닐까 싶다.
이것으로 서브쿼리에 대한 정리가 끝났다.
다음에는 DDL (CREATE) 테이블 생성에 대해 정리해보도록 하겠다!
'데이터베이스' 카테고리의 다른 글
| [8일차] DML(Data Manipulation Language), DDL(Data Definition Language) (0) | 2024.02.26 |
|---|---|
| [7일차] DDL(CREATE) (2) | 2024.02.25 |
| [5일차] JOIN (0) | 2024.02.23 |
| [4일차] GROUP함수 (0) | 2024.02.22 |
| [3일차] 함수의 마무리 (0) | 2024.02.19 |


