간단하게 GROUP함수들을 보도록 하자 !
SUM
해당컬럼 값들의 총 합계를 구해서 반환해주는 함수
[표현법]
SUM(숫자타입컬럼)
SELECT SUM(SALARY)
FROM EMPLOYEE;아주아주 간단하다. 원하는 컬럼을 넣어주면 컬럼의 모든 값을 더해서 반환해준다.
가볍게 하나만 더 보면
SELECT SUM(SALARY)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) IN ('1','3');EMP_NO는 주민등록번호이고 SUBSTR로 8번째의 값을 잘랐다. 123456-1****** 의 남자 여자를 가르는 뒷자리 첫 번째 숫자이다. 이것이 1,3 인 값의 SALARY를 모두 SUM해서 반환해주는 코드이다.
AVG
해당 컬럼값들의 평균값을 구해서 반환
[표현법]
AVG(NUMBER)
SELECT ROUND(AVG(SALARY))
FROM EMPLOYEE;이것도 아주 간단하다. (ROUND는 소수점을 버리는 함수였던거 모두 잊지말자 !)
MIN
해당 컬럼값 중 가장 작은 값 구해서 반환
MIN(모든 타입가능)
SELECT MIN(EMP_NAME), MIN(SALARY), MIN(HIRE_DATE)
FROM EMPLOYEE;말 그대로 제일 작은 값을 알아서 가져와준다. (SQL은 이런면에서 편리한 것 같다)
MAX
해당 컬럼값들 중에 가장 큰 값을 구해서 반환
MAX(모든 타입 가능)
SELECT MAX(EMP_NAME), MAX(SALARY), MAX(HIRE_DATE)
FROM EMPLOYEE;말 그대로 제일 큰 값을 알아서 가져와준다 !
COUNT
공통으로 행의 개수를 반환해준다는 특징을 가지고 있다.
COUNT(* | 컬럼 | DISTINCT 컬럼) : 해당 조건에 맞는 행의 개수를 세서 반환
COUNT(*) : 조회된 결과에 모든 행의 개수를 세서 반환
COUNT(컬럼) : 제시한 해당 컬럼값이 NULL이 아닌 것만 행의 개수를 세서 반환
COUNT(DKISTINCT 컬럼) : 해당 컬럼값 중복을 제거한 후 행의 개수를 세서 반환
SELECT COUNT(*) FROM EMPLOYEE;이렇게하면 EMPLOYEE 테이블의 모든 행을 가져오게되니 총직원의 수를 구할 수 있다.
SELECT COUNT(*)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8,1) IN('2','4');마찬가지로 EMP_NO는 주민등록번호이고 8번째의 1자리를 가져와서 2또는 4라면 COUNT해준다.
그럼 모든 여자사원들의 수를 구할 수 있다.
SELECT COUNT(BONUS)
FROM EMPLOYEE
WHERE BONUS IS NOT NULL;이것은 보너스를 받는 사람을 구하는 쿼리이다. BONUS에는 널 값이 있으며 이 쿼리를 실행해보면
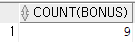
이렇게 9가 나오게된다. 하지만 여기서 COUNT 함수의 특징이 나오는데 COUNT함수는 IS NOT NULL 을 자동적으로 포함하고 있다. 즉 NULL인 값은 카운팅하지 않는다.
그럼 코드를 살짝 지워서 실행해보면
SELECT COUNT(BONUS)
FROM EMPLOYEE;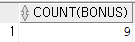
똑같이 9가 나오는 것을 알 수 있다.
SELECT COUNT(DISTINCT DEPT_CODE)
FROM EMPLOYEE;또 COUNT안에 DISTINCT를 사용할 수 있는데 DISTINCT는 중복제거임을 잊지말자 !!
GROUP BY
그룹기준을 제시할 수 있는 구문(해당 그룹기준별로 여러 그룹으로 묶을 수 있음)
여러개의 값들을 하나의 그룹으로 묶어서 처리하는 목적으로 사용
바로 예제를 봐보자
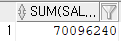
SELECT SUM(SALARY)
FROM EMPLOYEE;이렇게 한다면 모든 월급을 더해서 하나의 데이터로 표현해준다.
방금 배운 COUNT와 조금 더 응용해본다면
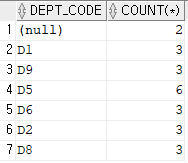
SELECT DEPT_CODE, COUNT(*)
FROM EMPLOYEE
GROUP BY DEPT_CODE;부서별로 묶어놓고 COUNT로 행의 개수를 샌다면 부서별로 있는 사원들의 수가 나오게 된다.
하지만 부서에 NULL이 있어서 NULL도 표현된다. (부서배치를 받지 않은사람 == NULL)
잠깐 번외로 가보겠다.
쿼리에서 실행순서는 상당히 중요한데 그 점을 보고 숙지해보겠다!
SELECT DEPT_CODE, COUNT(*), SUM(SALARY)--3
FROM EMPLOYEE----------------------------1
GROUP BY DEPT_CODE-----------------------2
ORDER BY DEPT_CODE;----------------------4쿼리의 실행순서는 이렇게 된다.
- 일단 EMPLOYEE테이블을 가져온다 (이것은 변하지않는다.)
- 그리고 DEPT_CODE로 CROUP BY를 해준다.
- SELECT로 원하는 것을 가져온다
- ORDER BY로 정렬한다 (이것도 변하지 않는다.)
변하지 않는다는게 무슨소리인가 하면 ORDER BY는 무조껀 마지막에 실행된다는 점이다.
반대로 FROM절은 제일 처음 시작된다.
이것을 알고 넘어가면 나중에 복잡한 쿼리를 짤때도 도움이 될 것 같아서 정리한다.
다음으로 GROUP BY 절에 여러 컬럼 기술가능한데 이것을 알아보겠다.
SELECT DEPT_CODE, JOB_CODE, COUNT(*), SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE
ORDER BY DEPT_CODE;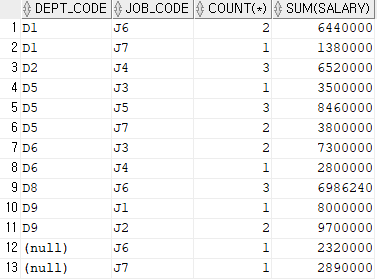
보면 중복된 값들이 꽤 보이는데 이것은 DEPT_CODE와 JOB_CODE를 서로 묶어 GROUP으로 만들었기 때문에
서로의 테이블을 합쳐서 값이 있다면 출력하게 되는 것이다.
우리는 GROUP이 아닌 단일행 함수에서 조건을 걸 때 WHERE 을 사용했었다.
하지만 GROUP으로 묶었을 때는 WHERE을 사용할 수 없다.
그래서 배우게 되는 HAVING == 그룹전용 WHERE 느낌이다!
HAVING
그룹에 대한 조건을 제시할 때 사용되는 구문(주로 그룹함수식을 가지고 조건을 만듬)
SELECT DEPT_CODE, ROUND(AVG(SALARY))
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING (AVG(SALARY))>=3000000;사용하는 방식은 똑같다.
우리가 WHERE을 사용했듯 WHERE 대신에 HAVING을 기술해주면 된다.
대신 단일 행 함수는 사용 불가능하니 혼동되지 않도록 함수의 기능을 다시 한 번 복기해보도록 하자!
SELECT DEPT_CODE
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING COUNT(BONUS) = 0;위 코드는 DEPT_CODE를 그룹으로 묶고 BONUS를 받지 못하는 사람을 찾는 코드이다.
위에서 방금 말했던 쿼리의 동작 순서를 기억하는가?
중요하기 때문에 다시 한 번 복기해보겠따
SELECT * | 조회하고싶은 컬럼 AS 별칭 | 함수식 | 산술연산식--------------5
FROM 조회하고자하는 테이블 | DUAL -----------------------1
WHERE 조건식 (연산자들을 활용하여 기술) -----------------------2
GROUP BY 그룹기준이 되는 컬럼 | 함수식 -----------------------3
HAVING 조건식(그룹 함수를 가지고 기술) -----------------------4
ORDER BY 컬럼 | 별칭 | 순서 [ASC | DESC] [NULLS FIRST | NULLS LAST] ---6잊지말자 언제나 일반적인 상황에서 FROM은 처음이고 ORDER BY는 마지막에 실행된다.
집합 연산자
여러개의 쿼리문을 하나의 쿼리문으로 만드는 연산자
UNION : OR | 합집합(두 쿼리문 수행한 결과값을 더한다.)
INTERSECT : AND | 교집합 (두 쿼리문을 수행한 결과값에 중복된 결과값)
UNION ALL : 합집합 + 교집합 (중복되는게 두 번 표현될 수 있다.)
MINUS : 차집합(선행결과값에 후행결과값을 뺀 나머지)
UNION
먼저 우리가 예전에 하던 방식으로도 가능한데 밑 코드는 UNION을 사용하지 않고
조건 : 부서코드가 D5인 사원 또는 급여가 300만원 초과인 사원들의 사번, 이름, 부서코드, 급여조회 를 맞춰 쿼리를 작성했다
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5' OR SALARY > 3000000;원래 하던대로 OR을 사용하여 조건을 맞추었다.
그럼 위 코드를 쪼개서 보면
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5';이렇게 두개가 나오게 된다. (단순하게 OR을 뜯은 것 이다.)
그럼 위 두 코드를 UNION을 이용하여 합쳐보면
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;그냥 코드 사이에 UNION 을 기술해주면 된다.
두 코드사이에 다리를 놔주는 느낌이다.
그럼 여기서 의문이 드는데 이걸 굳이 왜 이렇게 사용할까? 라는 생각이 들어 질문했더니 지금 이렇게 보면 코드가 간단하고 쉽지만 현업에가면 복잡하고 헷갈리는 코드가 생기는데 이것을 명확하게 해결하기 위해서 사용된다고 하셨다.
듣고보니 괜히 한 쿼리로 합치는 것 보다는 이렇게 하는게 훨씬 가독성 좋고 오류가 날 확률이 적어보였다
INTERSECT(교집합)
위에서 했던 것과 똑같다.
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5' AND SALARY > 3000000;이렇게 WHERE절에 AND로 이어진 조건이 있을 때
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
INTERSECT
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;두 쿼리를 뜯어서 INTERSECT로 이어주면 된다 !
이것은 AND라는 것을 잊지말자
UNION ALL
여러개의 쿼리 결과를 무조건 다 더하는 연산자
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION ALL
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000
ORDER BY EMP_ID;위 처음 쿼리와 두 번째 쿼리의 결과를 더하는 연산자이다 !
MINUS
선행 SELECT 결과에서 후행 SELECT 결과를 뺀 나머지(차집합)
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
MINUS
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000
ORDER BY EMP_ID;반대로 위 처음 쿼리 결과에서 두 번째 쿼리 결과를 뺀 것이다 !
이렇게 GROUP 함수가 마무리 됐고 다음은 두 테이블을 합치는 JOIN을 공부해보겠습니다.
'데이터베이스' 카테고리의 다른 글
| [6일차] SUBQUERY (0) | 2024.02.24 |
|---|---|
| [5일차] JOIN (0) | 2024.02.23 |
| [3일차] 함수의 마무리 (0) | 2024.02.19 |
| [2일차] SELECT 마무리와 FUNTION 기능들 (2) | 2024.02.16 |
| [1일차] 데이터베이스, Oracle SQL입문 (4) | 2024.02.15 |


