
[1일차] 데이터베이스, Oracle SQL입문
오늘은 오라클에 입문해보았다.
그럼 오라클에 대해 알아보기전에 데이터베이스를 먼저 알아보자.
데이터 베이스란?
데이터베이스는 구조화된 정보 또는 데이터의 조직화된 모음으로써 컴퓨터 시스템에 저장된다.
이것을 관리하는게 데이터베이스 관리 시스템 (DBMS)이다.
데이터와 연결된 애플리케이션 + DBMS를 하나로 묶어 표현하는 것이 데이터 베이스이다.
-oracle 홈페이지-
데이터 베이스의 유형
- 관계형 데이터베이스 : 열과 행이 있는 테이블의 집합, 정형화된 정보에 가장 효율적이고 유연하게 액세스가능하다.
- 객체지향 데이터베이스 : 우리가 아는 객체지향 프로그래밍과 마찬가지로 정보가 객체형태로 표현된다.
- 분산 데이터베이스 : 서로 다른 사이트에 위치한 둘 이상의 파일로 구성된다. ex)물리적으로 동일한 위치에 있는 여러 컴퓨터에 나눠서 저장하거나 다르 네트워크로 분산해서 저장이 가능하다.
- 데이터 웨어하우스 : 데이터의 중앙저장소라고 불리는 곳이다. 빠른 쿼리 및 분석을 위해 특별히 설계되었다.
- NoSQL 데이터베이스 : 비관계형 데이터베이스이다. 특징으로는 비정형 및 반정형 데이터를 저장하고 조작할 수 있다.
- 그래프 데이터베이스 : 엔티티 및 엔티티 간의 관계 측면에서 데이터를 저장한다.
- OLTP데이터베이스 : 여러 사용자가 수행하는 많은 수의 트랜잭션을 위해 설계된 고속 분석 데이터 베이스이다.
여기까지가 오늘 날의 일반적인 데이터베이스들이다..
이 밑으로는 최신 데이터베이스들을 소개해본다
- 오픈소스 데이터베이스 : 시스템 소스코드가 오픈소스인 시스템이다. SQL과 NoSQL 데이터베이스가 여기에 해당된다.
- 클라우드 데이터베이스 : 프라이빗, 퍼블릭 또는 하이브리드 클라우드 컴퓨팅 플랫폼에 상주하는 정형 또는 비정형 데이터의 모음이다. 예로 DBaaS 가 있다.
- 다중 모델 데이터베이스 : 서로 다른 유형의 데이터베이스 모델을 단일 통합 백엔드로 결합한 것이다. 다양한 데이터 유형을 수용할 수 있다는 장점이 있다.
- 문서/JONS데이터 베이스 : 문서 지향 정보를 저장, 검색 및 관리하도록 설계되었고 행과 열이아닌 JSON형식으로 데이터를 저장하는 최신 방식이다.
- 자율 운영 데이터베이스 : 자율구동(운영) 데이터베이스는 클라우드를 기반으로 하며 머신러닝을 사용하여 데이터베이스 튜닝, 보안, 백업 업데이트 및 기타 데이터베이스 관리자가 하는 일을 대신해서 진행해준다.
여기까지가 데이터베이스에 대한 이론이다.
지금부터는 배웠던 SQL을 복습하는 느낌으로 포스팅을 해보려한다.
SQL은 어렵진 않지만 가면 갈 수록 방대한 양이 더해져서 헷갈리고 어려워질 수 있다고 하니 복습을 철저하게 해서 어렵지않게 느낄 수 있도록 해보겠따
SQL(Structured Query Language) 이란?
관계형 데이터베이스에서 데이터를 정의하고 조작하기 위해 표준화된 언어.
데이터베이스에서 원하는 데이터를 추출하고 분석하는데 도움을 주는 쿼리(Query) 언어1 시장 트렌드 분석이나 고객 행동 패턴 파악 등을 통해 데이터를 뽑아서 전략을 세우기 용이하다.
그럼 SQL 언어를 사용하기위해 해야 할 것은 뭘까,
데이터베이스를 관리하고자 하면 위에서 나왔던 DBMS(데이터관리 시스템)을 설치하고 이에 맞는 SQL프로그램을 선택한다.
대표적인 DBMS 3가지를 알아보자!
Oracle
- 대규모 기업용 데이터베이스이다.
- 리눅스 환경에서 가장 많이 사용된다
- 안정성과 확장성이 높다
MySQL
- 오픈소스 기반의 관계형 데이터베이스 관리 시스템이다.
- 빠르고 높은 성능을 가지고있다
- 설치와 사용이 가볍기 때문에 웹 애플리케이션과 소규모에 많이 사용된다
MY SQL(Microsoft)
- Microsoft에서 나온 관계형 데이터베이스 관리시스템이다.
- windows 운영체제에서 가장 좋다
- 편리한 관리도구와 호환성이 좋기때문에 기업용 솔루션으로 사용된다.
이제는 Oracle의 SQL Developer 을 사용해여 공부해보자
일단 1일차에 느낀 것은 엑셀시트에 저장하고 그것을 꺼내오는 느낌이였다.

실제로 SQL의 테이블은 언뜻보면 엑셀을 보는 느낌이다.
그럼 엑셀과 SQL이 뭐가 다른 것일까
- 데이터 베이스에 저장하고 조작하는게 훨씬 편하다
- 데이터에 액세스 할 수 있는 사람을 관리자가 세세하게 저장해줄 수 있다.
- 저장할 수 있는 데이터의 양이 말도안되게 크다.(기업용이니까 당연하지)
아 그리고 SQL은 왠지 관습으로 모두 대문자만 사용한다고 한다.
나는 코딩관습은 똑똑한 사람들이 그러면 편하다고 만들어놓았다고 생각한다.(또는 무언의 약속)
그러므로 따지지말고 바로 수용해서 따라하자
먼저 주석하는 방법이다.
우리가 일반적으로 다른 언어에서 사용하던 주석이 가능하다.
다만 한 줄 주석은 좀 다른데
이런식으로 -- 를 사용한다.
제일 위에 나왔던 주석 방법에 SELECT 명령어가 있다.
그럼 EMPLOYEE 테이블에 모든 정보를 가져오고싶다면 어떻게 할까?
SELECT * FROM EMPLOYEE;프로그래밍 할 때 모든 정보를 가져온다면 *이다.
예로 자바에서 import시 모두 import 하고싶다면 *을 사용했었던 것을 기억해보자.
그럼 위 코드는 EMPLOYEE테이블에 있는 모든 컬럼을 가져오게된다. 2
솔직히 어렵지 않다. 빠르게 읽어보면서 이해하고 감을 잡으면 된다.
--모든 사원의 이름, 주민등록번호, 핸드폰 번호
SELECT EMP_NAME, EMP_NO, PHONE
FROM EMPLOYEE;
--EMPLOYEE 테이블의 사원명, 이메일 ,전화번호 ,입사일, 급여 조회
SELECT EMP_NAME, EMAIL, PHONE, HIRE_DATE, SALARY
FROM EMPLOYEE;
그리고 우리가 불러온 컬럼 값에 산술연산을 더해줄 수가 있다.
--EMPLOYEE 테이블의 사원명, 사원의 연봉(SALARY * 12)을 조회
SELECT EMP_NAME, SALARY * 12
FROM EMPLOYEE;
이런식으로 산술연산을 해주면 된다.
하나만 더 보면
--EMPLOYEE테이블의 사원명, 급여, 보너스, 연봉, 보너스포함연봉 조회(급여 + (급여 * 보너스)) *12
SELECT * FROM EMPLOYEE;
SELECT EMP_NAME, SALARY, BONUS, SALARY * 12, (SALARY + (SALARY * BONUS)) * 12
FROM EMPLOYEE;보너스 포함 연봉 계산을 보면 컬럼값을 넣고 산술연산도 가능하다는 것을 알 수있다.
하지만 보너스가 null(비어있음)이라면 연산 결과가 어떻게 될까?
-> 0을 곱한 것과 같다, 모든 숫자에 0을 곱하면 0이다.
마찬가지로 null을 곱하면 모두 null이 되버린다.
--사원명, 입사일, 근무일수를 조회
--현재시간 - 입사일 = 근무한시간
--DATE - DATE =>결과는 무조건 일로 표시가된다.
--코드실행시 날짜를 표시하는 상수 SYSDATE : [년/월/일/시/분/초]
SELECT EMP_NAME, HIRE_DATE, SYSDATE - HIRE_DATE
FROM EMPLOYEE;위 코드에서는 SYSDATE에 집중하면 된다.
그리고 DUAL 이라는 게 있는데 이것은 더미데이터라 불리며 아무것도 없는 표에 내가 원한는 것을 출력한다고 보면 된다
SELECT SYSDATE FROM DUAL;이렇게하면 아무것도 없던 표에 코드 실행시의 날짜와 시간을 적어서 보여준다.
그리고 별칭을 지정해 줄 수 있다. 별칭은 뭘까 밑에 코드를 봐보자.
SELECT EMP_NAME, SALARY, BONUS, SALARY * 12
FROM EMPLOYEE;이 코드를 실행 할 경우
위에 컬럼 값을 보면 COLUMN_NAME 이런식으로 나오는데 이것을 우리가 보기 편하게 "별칭"으로 바꿔 줄 수 있다.
사용법은 SELECT 컬럼명 AS 별칭
SELECT 컬럼명 "별칭"
SELECT 컬럼명 AS "별칭"
세가지 모두 지원한다!
SELECT EMP_NAME 사원명, SALARY AS 월급, BONUS "보너스", SALARY * 12 AS "연봉(원)"
FROM EMPLOYEE;이 코드를 실행하면

이렇게 바뀌게된다.
하지만 우리가 별칭으로 한글을 지정할 일은 거의 없다고 보면된다 .....
다음으로 리터럴 이라는 것이 있다.
조회된 결과의 모든 행에 반복적으로 출력하고 싶을 때가 있다.
--EMPLOYEE 테이블의 사번, 사원명, 급여
SELECT EMP_ID, EMP_NAME, SALARY, '원'AS "단위"
FROM EMPLOYEE;
이렇게 ' ' 작은 따옴표 안에 쓰게 된다면 출력 값은

이렇게 원래 컬럼명에 없던 단위와 단위의 값 원이 자동으로 출력된다.
다음은 || 이다. 자바에서는 OR로 쓰였지만 SQL에서는 모든 컬럼을 하나의 컬럼으로 조회하는 기능이다.
--사번, 이름 급여를 하나의 컬럼으로 조회
SELECT EMP_ID || EMP_NAME || SALARY
FROM EMPLOYEE;

다음은 중복제거이다. 사용법은 SELECT와 컬럼명 사이에 DISTINCT를 넣어주면 된다.
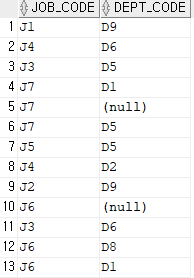
--EMPLOYEE 부서코드를 조회(중복제거)
SELECT DISTINCT DEPT_CODE
FROM EMPLOYEE;


*주의사항으로 DISTINCT는 한 번만 사용이 가능하다. 예를들어
SELECT DISTINCT JOB_CODE, DEPT_CODE
FROM EMPLOYEE;
이렇게 두 개의 컬럼을 묶어서 사용하게 된다면 쌍으로 묶어서 제거한 값을 보여준다.
<WHERE 절>
조회하고자하는 테이블로부터 특정 조건에 만족하는 데이터만을 조회할 때 사용
조건식에서도 다양한 연산자 사용이 가능
[표현법]
SELECT 컬럼, 컬럼, 컬럼 연산
FROM 테이블
WHERE 조건;
>>비교연산자<<
>, <, >=, <= : 대소비교
= : 양쪽이 같다
!=, ^=, <> : 양쪽이 다르다.
우리가 자바에서 사용할 때 쓰던 if문 느낌이다.
어렵지 않으니 간단한 코드만 몇 개 보면 바로 이해할 수 있다.
--EMPLOYEE에서 부서코드가 'D9'인 사원들만 조회(모든컬럼)
SELECT *
FROM EMPLOYEE
WHERE DEPT_CODE = 'D9';

-2-
--EMPLOYEE에서 부서코드가 'D1'인 아닌 사원들의 사원명, 급여, 부서코드를 조회
SELECT EMP_NAME, SALARY, DEPT_CODE
FROM EMPLOYEE
WHERE DEPT_CODE != 'D1';
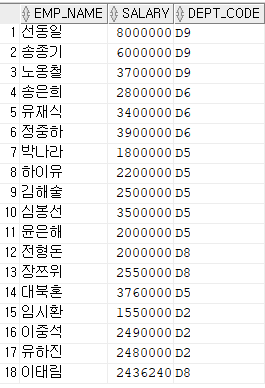
-3-
--월급이 400만원 이상인 사원들의 사원명, 부서코드, 급여 조회
SELECT EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 4000000;
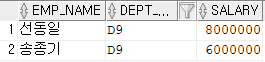
이런식으로 WHERE을 사용해 조건을 걸어줄 수 있다.
오늘은 여기까지
데이터베이스는 솔직히 이해라기보단 직관적으로 받아들이는게 공부하기 편한 것 같다.